Converting to and from Document-Term Matrix and Corpus objects
Julia Silge and David Robinson
2024-04-10
Source:vignettes/tidying_casting.Rmd
tidying_casting.RmdTidying document-term matrices
Many existing text mining datasets are in the form of a
DocumentTermMatrix class (from the tm package). For
example, consider the corpus of 2246 Associated Press articles from the
topicmodels package:
## <<DocumentTermMatrix (documents: 2246, terms: 10473)>>
## Non-/sparse entries: 302031/23220327
## Sparsity : 99%
## Maximal term length: 18
## Weighting : term frequency (tf)If we want to analyze this with tidy tools, we need to turn it into a
one-term-per-document-per-row data frame first. The tidy
function does this. (For more on the tidy verb, see the broom package).
Just as shown in this vignette, having the text in this format is convenient for analysis with the tidytext package. For example, you can perform sentiment analysis on these newspaper articles.
ap_sentiments <- ap_td %>%
inner_join(get_sentiments("bing"), join_by(term == word))
ap_sentiments## # A tibble: 30,094 × 4
## document term count sentiment
## <int> <chr> <dbl> <chr>
## 1 1 assault 1 negative
## 2 1 complex 1 negative
## 3 1 death 1 negative
## 4 1 died 1 negative
## 5 1 good 2 positive
## 6 1 illness 1 negative
## 7 1 killed 2 negative
## 8 1 like 2 positive
## 9 1 liked 1 positive
## 10 1 miracle 1 positive
## # ℹ 30,084 more rowsWe can find the most negative documents:
library(tidyr)
ap_sentiments %>%
count(document, sentiment, wt = count) %>%
pivot_wider(names_from = sentiment, values_from = n, values_fill = 0) %>%
mutate(sentiment = positive - negative) %>%
arrange(sentiment)## # A tibble: 2,190 × 4
## document negative positive sentiment
## <int> <dbl> <dbl> <dbl>
## 1 1251 54 6 -48
## 2 1380 53 5 -48
## 3 531 51 9 -42
## 4 43 45 11 -34
## 5 1263 44 10 -34
## 6 2178 40 6 -34
## 7 334 45 12 -33
## 8 1664 38 5 -33
## 9 2147 47 14 -33
## 10 516 38 6 -32
## # ℹ 2,180 more rowsOr visualize which words contributed to positive and negative sentiment:
library(ggplot2)
ap_sentiments %>%
count(sentiment, term, wt = count) %>%
group_by(sentiment) %>%
slice_max(n, n = 10) %>%
mutate(term = reorder(term, n)) %>%
ggplot(aes(n, term, fill = sentiment)) +
geom_col(show.legend = FALSE) +
facet_wrap(vars(sentiment), scales = "free_y") +
labs(x = "Contribution to sentiment", y = NULL)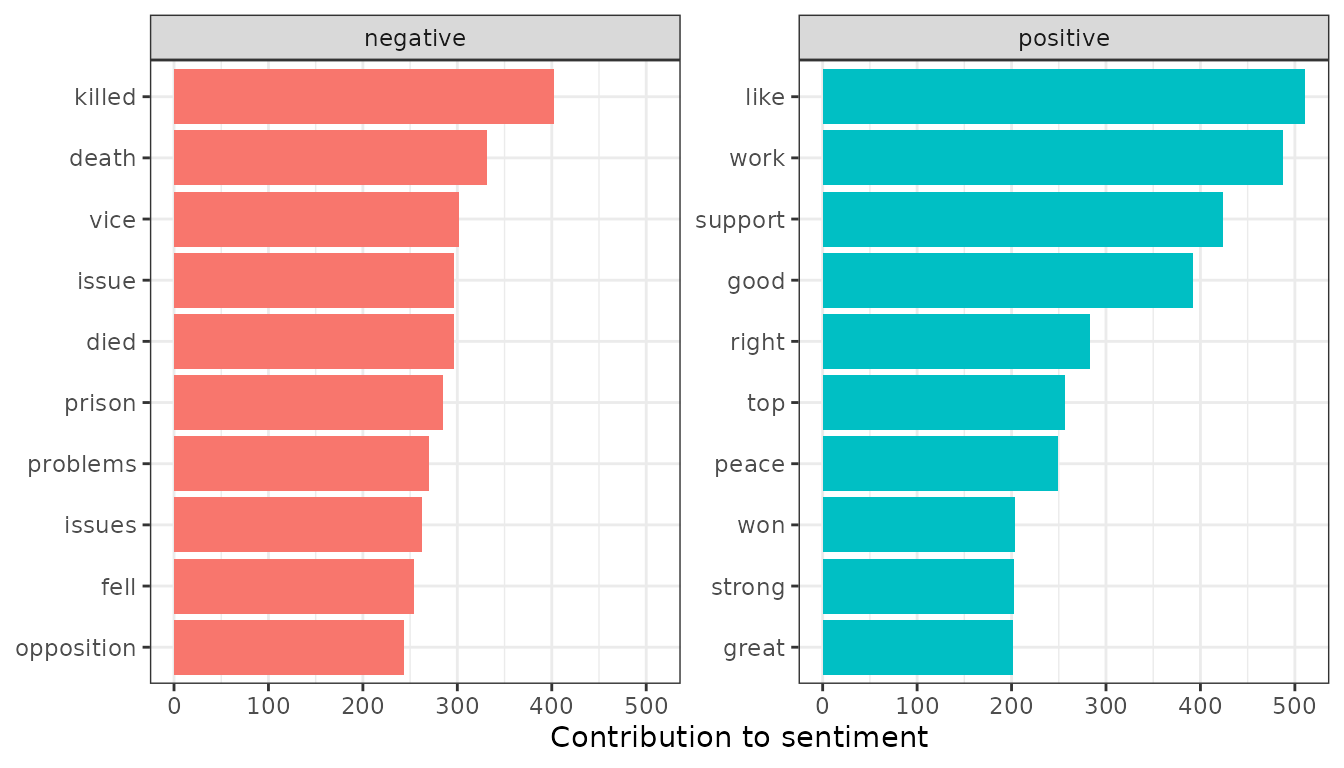
Note that a tidier is also available for the dfm class
from the quanteda package:
library(methods)
data("data_corpus_inaugural", package = "quanteda")
d <- quanteda::tokens(data_corpus_inaugural) %>%
quanteda::dfm()
d## Document-feature matrix of: 59 documents, 9,437 features (91.84% sparse) and 4 docvars.
## features
## docs fellow-citizens of the senate and house representatives :
## 1789-Washington 1 71 116 1 48 2 2 1
## 1793-Washington 0 11 13 0 2 0 0 1
## 1797-Adams 3 140 163 1 130 0 2 0
## 1801-Jefferson 2 104 130 0 81 0 0 1
## 1805-Jefferson 0 101 143 0 93 0 0 0
## 1809-Madison 1 69 104 0 43 0 0 0
## features
## docs among vicissitudes
## 1789-Washington 1 1
## 1793-Washington 0 0
## 1797-Adams 4 0
## 1801-Jefferson 1 0
## 1805-Jefferson 7 0
## 1809-Madison 0 0
## [ reached max_ndoc ... 53 more documents, reached max_nfeat ... 9,427 more features ]
tidy(d)## # A tibble: 45,452 × 3
## document term count
## <chr> <chr> <dbl>
## 1 1789-Washington fellow-citizens 1
## 2 1797-Adams fellow-citizens 3
## 3 1801-Jefferson fellow-citizens 2
## 4 1809-Madison fellow-citizens 1
## 5 1813-Madison fellow-citizens 1
## 6 1817-Monroe fellow-citizens 5
## 7 1821-Monroe fellow-citizens 1
## 8 1841-Harrison fellow-citizens 11
## 9 1845-Polk fellow-citizens 1
## 10 1849-Taylor fellow-citizens 1
## # ℹ 45,442 more rowsCasting tidy text data into a DocumentTermMatrix
Some existing text mining tools or algorithms work only on sparse
document-term matrices. Therefore, tidytext provides cast_
verbs for converting from a tidy form to these matrices.
ap_td## # A tibble: 302,031 × 3
## document term count
## <int> <chr> <dbl>
## 1 1 adding 1
## 2 1 adult 2
## 3 1 ago 1
## 4 1 alcohol 1
## 5 1 allegedly 1
## 6 1 allen 1
## 7 1 apparently 2
## 8 1 appeared 1
## 9 1 arrested 1
## 10 1 assault 1
## # ℹ 302,021 more rows## <<DocumentTermMatrix (documents: 2246, terms: 10473)>>
## Non-/sparse entries: 302031/23220327
## Sparsity : 99%
## Maximal term length: 18
## Weighting : term frequency (tf)## <<TermDocumentMatrix (terms: 10473, documents: 2246)>>
## Non-/sparse entries: 302031/23220327
## Sparsity : 99%
## Maximal term length: 18
## Weighting : term frequency (tf)## Document-feature matrix of: 10,473 documents, 2,246 features (98.72% sparse) and 0 docvars.
## features
## docs 1 2 3 4 5 6 7 8 9 10
## adding 1 0 0 0 0 0 0 0 0 0
## adult 2 0 0 0 0 0 0 0 0 0
## ago 1 0 1 3 0 2 0 0 0 0
## alcohol 1 0 0 0 0 0 0 0 0 0
## allegedly 1 0 0 0 0 0 0 0 0 0
## allen 1 0 0 0 0 0 0 0 0 0
## [ reached max_ndoc ... 10,467 more documents, reached max_nfeat ... 2,236 more features ]
# cast into a Matrix object
m <- ap_td %>%
cast_sparse(document, term, count)
class(m)## [1] "dgCMatrix"
## attr(,"package")
## [1] "Matrix"
dim(m)## [1] 2246 10473This allows for easy reading, filtering, and processing to be done using dplyr and other tidy tools, after which the data can be converted into a document-term matrix for machine learning applications.
Tidying corpus data
You can also tidy Corpus objects from the tm package. For example, consider a Corpus containing 20 documents, one for each
reut21578 <- system.file("texts", "crude", package = "tm")
reuters <- VCorpus(DirSource(reut21578),
readerControl = list(reader = readReut21578XMLasPlain))
reuters## <<VCorpus>>
## Metadata: corpus specific: 0, document level (indexed): 0
## Content: documents: 20The tidy verb creates a table with one row per
document:
reuters_td <- tidy(reuters)
reuters_td## # A tibble: 20 × 17
## author datetimestamp description heading id language origin topics
## <chr> <dttm> <chr> <chr> <chr> <chr> <chr> <chr>
## 1 NA 1987-02-26 17:00:56 "" DIAMON… 127 en Reute… YES
## 2 BY TED … 1987-02-26 17:34:11 "" OPEC M… 144 en Reute… YES
## 3 NA 1987-02-26 18:18:00 "" TEXACO… 191 en Reute… YES
## 4 NA 1987-02-26 18:21:01 "" MARATH… 194 en Reute… YES
## 5 NA 1987-02-26 19:00:57 "" HOUSTO… 211 en Reute… YES
## 6 NA 1987-03-01 03:25:46 "" KUWAIT… 236 en Reute… YES
## 7 By Jere… 1987-03-01 03:39:14 "" INDONE… 237 en Reute… YES
## 8 NA 1987-03-01 05:27:27 "" SAUDI … 242 en Reute… YES
## 9 NA 1987-03-01 08:22:30 "" QATAR … 246 en Reute… YES
## 10 NA 1987-03-01 18:31:44 "" SAUDI … 248 en Reute… YES
## 11 NA 1987-03-02 01:05:49 "" SAUDI … 273 en Reute… YES
## 12 NA 1987-03-02 07:39:23 "" GULF A… 349 en Reute… YES
## 13 NA 1987-03-02 07:43:22 "" SAUDI … 352 en Reute… YES
## 14 NA 1987-03-02 07:43:41 "" KUWAIT… 353 en Reute… YES
## 15 NA 1987-03-02 08:25:42 "" PHILAD… 368 en Reute… YES
## 16 NA 1987-03-02 11:20:05 "" STUDY … 489 en Reute… YES
## 17 NA 1987-03-02 11:28:26 "" STUDY … 502 en Reute… YES
## 18 NA 1987-03-02 12:13:46 "" UNOCAL… 543 en Reute… YES
## 19 By BERN… 1987-03-02 14:38:34 "" NYMEX … 704 en Reute… YES
## 20 NA 1987-03-02 14:49:06 "" ARGENT… 708 en Reute… YES
## # ℹ 9 more variables: lewissplit <chr>, cgisplit <chr>, oldid <chr>,
## # topics_cat <named list>, places <named list>, people <chr>, orgs <chr>,
## # exchanges <chr>, text <chr>Similarly, you can tidy a corpus object
from the quanteda package:
## Corpus consisting of 59 documents and 4 docvars.
## 1789-Washington :
## "Fellow-Citizens of the Senate and of the House of Representa..."
##
## 1793-Washington :
## "Fellow citizens, I am again called upon by the voice of my c..."
##
## 1797-Adams :
## "When it was first perceived, in early times, that no middle ..."
##
## 1801-Jefferson :
## "Friends and Fellow Citizens: Called upon to undertake the du..."
##
## 1805-Jefferson :
## "Proceeding, fellow citizens, to that qualification which the..."
##
## 1809-Madison :
## "Unwilling to depart from examples of the most revered author..."
##
## [ reached max_ndoc ... 53 more documents ]
inaug_td <- tidy(data_corpus_inaugural)
inaug_td## # A tibble: 59 × 5
## text Year President FirstName Party
## <chr> <int> <chr> <chr> <fct>
## 1 "Fellow-Citizens of the Senate and of the Ho… 1789 Washingt… George none
## 2 "Fellow citizens, I am again called upon by … 1793 Washingt… George none
## 3 "When it was first perceived, in early times… 1797 Adams John Fede…
## 4 "Friends and Fellow Citizens:\n\nCalled upon… 1801 Jefferson Thomas Demo…
## 5 "Proceeding, fellow citizens, to that qualif… 1805 Jefferson Thomas Demo…
## 6 "Unwilling to depart from examples of the mo… 1809 Madison James Demo…
## 7 "About to add the solemnity of an oath to th… 1813 Madison James Demo…
## 8 "I should be destitute of feeling if I was n… 1817 Monroe James Demo…
## 9 "Fellow citizens, I shall not attempt to des… 1821 Monroe James Demo…
## 10 "In compliance with an usage coeval with the… 1825 Adams John Qui… Demo…
## # ℹ 49 more rowsThis lets us work with tidy tools like unnest_tokens to
analyze the text alongside the metadata.
inaug_words <- inaug_td %>%
unnest_tokens(word, text) %>%
anti_join(stop_words)
inaug_words## # A tibble: 50,965 × 5
## Year President FirstName Party word
## <int> <chr> <chr> <fct> <chr>
## 1 1789 Washington George none fellow
## 2 1789 Washington George none citizens
## 3 1789 Washington George none senate
## 4 1789 Washington George none house
## 5 1789 Washington George none representatives
## 6 1789 Washington George none vicissitudes
## 7 1789 Washington George none incident
## 8 1789 Washington George none life
## 9 1789 Washington George none event
## 10 1789 Washington George none filled
## # ℹ 50,955 more rowsWe could then, for example, see how the appearance of a word changes over time:
inaug_freq <- inaug_words %>%
count(Year, word) %>%
complete(Year, word, fill = list(n = 0)) %>%
group_by(Year) %>%
mutate(year_total = sum(n), percent = n / year_total) %>%
ungroup()
inaug_freq## # A tibble: 514,834 × 5
## Year word n year_total percent
## <int> <chr> <int> <int> <dbl>
## 1 1789 1 0 529 0
## 2 1789 1,000 0 529 0
## 3 1789 100 0 529 0
## 4 1789 100,000,000 0 529 0
## 5 1789 108 0 529 0
## 6 1789 11 0 529 0
## 7 1789 120,000,000 0 529 0
## 8 1789 125 0 529 0
## 9 1789 13 0 529 0
## 10 1789 14th 1 529 0.00189
## # ℹ 514,824 more rowsFor example, we can use the broom package to perform logistic regression on each word.
library(broom)
models <- inaug_freq %>%
group_by(word) %>%
filter(sum(n) > 50) %>%
group_modify(
~ tidy(glm(cbind(n, year_total - n) ~ Year, ., family = "binomial"))
) %>%
ungroup() %>%
filter(term == "Year")
models## # A tibble: 115 × 6
## word term estimate std.error statistic p.value
## <chr> <chr> <dbl> <dbl> <dbl> <dbl>
## 1 act Year 0.00645 0.00207 3.11 1.85e- 3
## 2 action Year 0.00154 0.00186 0.825 4.09e- 1
## 3 administration Year -0.00696 0.00182 -3.83 1.29e- 4
## 4 america Year 0.0202 0.00147 13.7 6.29e-43
## 5 american Year 0.00854 0.00122 6.99 2.71e-12
## 6 americans Year 0.0310 0.00321 9.65 5.01e-22
## 7 authority Year -0.00616 0.00229 -2.69 7.11e- 3
## 8 business Year 0.00271 0.00194 1.40 1.63e- 1
## 9 called Year -0.00158 0.00198 -0.799 4.24e- 1
## 10 century Year 0.0145 0.00231 6.27 3.58e-10
## # ℹ 105 more rows## # A tibble: 115 × 6
## word term estimate std.error statistic p.value
## <chr> <chr> <dbl> <dbl> <dbl> <dbl>
## 1 americans Year 0.0310 0.00321 9.65 5.01e-22
## 2 america Year 0.0202 0.00147 13.7 6.29e-43
## 3 democracy Year 0.0156 0.00223 6.99 2.70e-12
## 4 children Year 0.0149 0.00246 6.06 1.36e- 9
## 5 century Year 0.0145 0.00231 6.27 3.58e-10
## 6 god Year 0.0135 0.00179 7.58 3.36e-14
## 7 live Year 0.0128 0.00232 5.50 3.70e- 8
## 8 powers Year -0.0125 0.00196 -6.38 1.76e-10
## 9 revenue Year -0.0122 0.00250 -4.87 1.11e- 6
## 10 foreign Year -0.0120 0.00191 -6.31 2.73e-10
## # ℹ 105 more rowsYou can show these models as a volcano plot, which compares the effect size with the significance:
library(ggplot2)
models %>%
mutate(adjusted.p.value = p.adjust(p.value)) %>%
ggplot(aes(estimate, adjusted.p.value)) +
geom_point() +
scale_y_log10() +
geom_text(aes(label = word), vjust = 1, hjust = 1, check_overlap = TRUE) +
labs(x = "Estimated change over time", y = "Adjusted p-value")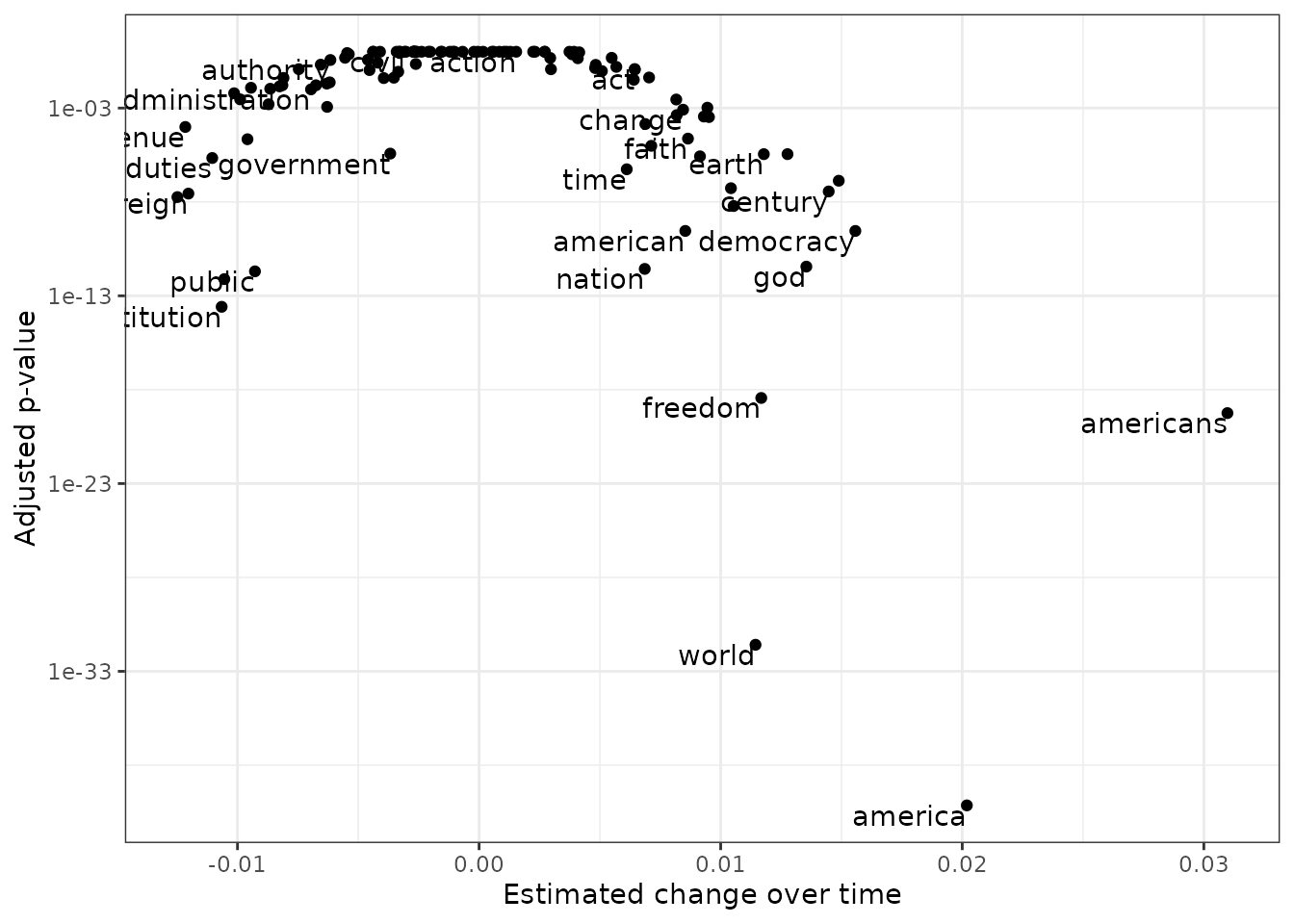
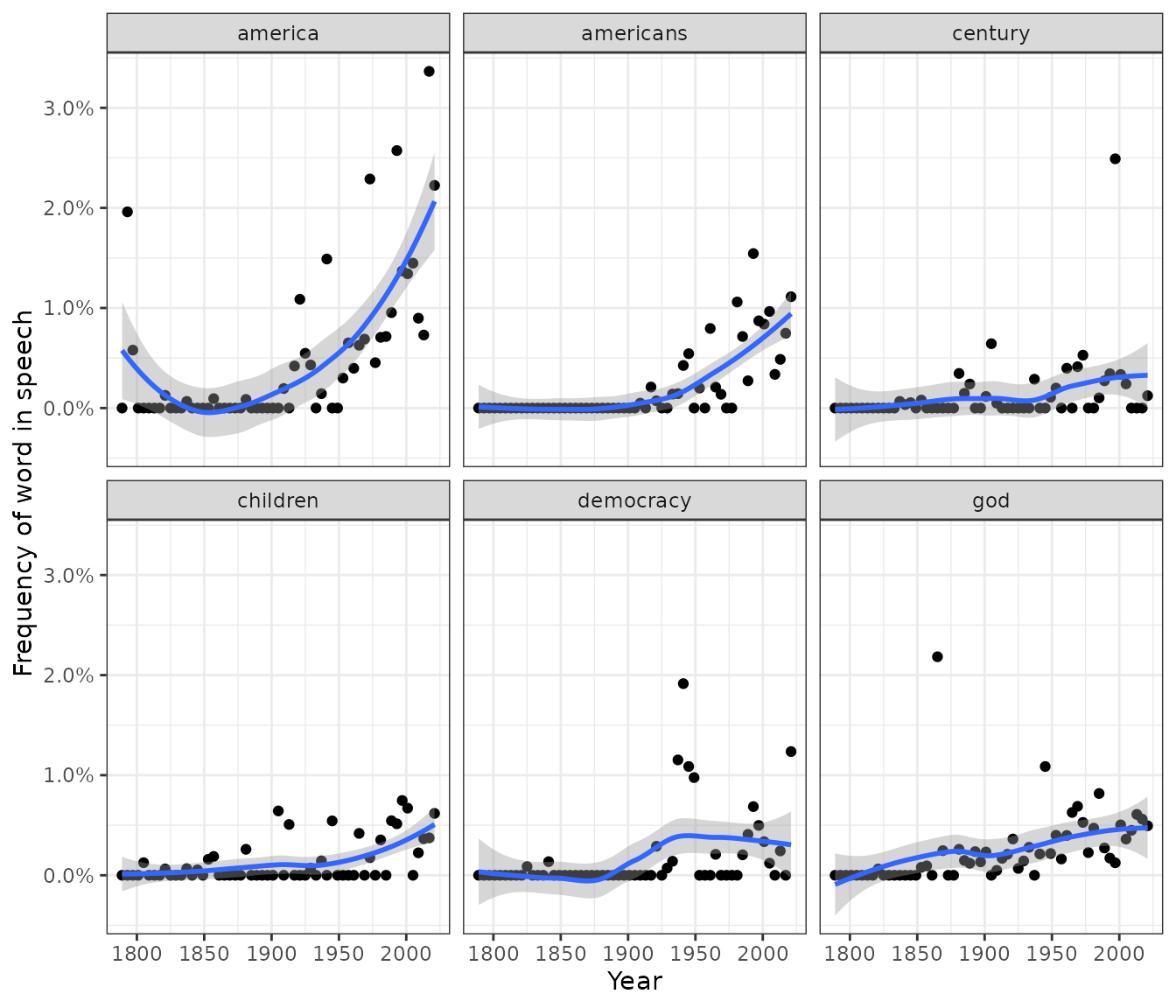
We can also use the ggplot2 package to display the top 6 terms that have changed in frequency over time.
library(scales)
models %>%
slice_max(abs(estimate), n = 6) %>%
inner_join(inaug_freq) %>%
ggplot(aes(Year, percent)) +
geom_point() +
geom_smooth() +
facet_wrap(vars(word)) +
scale_y_continuous(labels = percent_format()) +
labs(y = "Frequency of word in speech")