Text Mining
USING TIDY DATA PRINCIPLES
Hello!

Join our workspace on Posit Cloud
Or alternatively, install the packages yourself to work locally:
Text in the real world
Text data is increasingly important 📚
NLP training is scarce on the ground 😱
TIDY DATA PRINCIPLES + TEXT MINING = 🎉

GitHub repo for workshop:
Plan for this workshop
EDA for text
Modeling for text
What do we mean by tidy text?
text <- c("Dice la tarde: '¡Tengo sed de sombra!'",
"Dice la luna: '¡Yo, sed de luceros!'",
"La fuente cristalina pide labios",
"y suspira el viento.")
text
#> [1] "Dice la tarde: '¡Tengo sed de sombra!'"
#> [2] "Dice la luna: '¡Yo, sed de luceros!'"
#> [3] "La fuente cristalina pide labios"
#> [4] "y suspira el viento."Cantos Nuevos by Federico García Lorca
What do we mean by tidy text?
Cantos Nuevos by Federico García Lorca
What do we mean by tidy text?
Cantos Nuevos by Federico García Lorca
Gathering more data
You can access the full text of many public domain works from Project Gutenberg using the gutenbergr package.
What book do you want to analyze today? 📖🥳📖
Time to tidy your text!
tidy_book <- full_text |>
mutate(line = row_number()) |>
unnest_tokens(word, text)
glimpse(tidy_book)
#> Rows: 383,636
#> Columns: 3
#> $ gutenberg_id <int> 2000, 2000, 2000, 2000, 2000, 2000, 2000, 2000, 2000, 200…
#> $ line <int> 1, 1, 1, 1, 1, 1, 1, 1, 5, 5, 5, 5, 5, 11, 11, 11, 11, 11…
#> $ word <chr> "el", "ingenioso", "hidalgo", "don", "quijote", "de", "la…What are the most common words?
What do you predict will happen if we run the following code? 🤔
What are the most common words?
What do you predict will happen if we run the following code? 🤔
STOP WORDS 🛑
Stop words
Stop words
Stop words
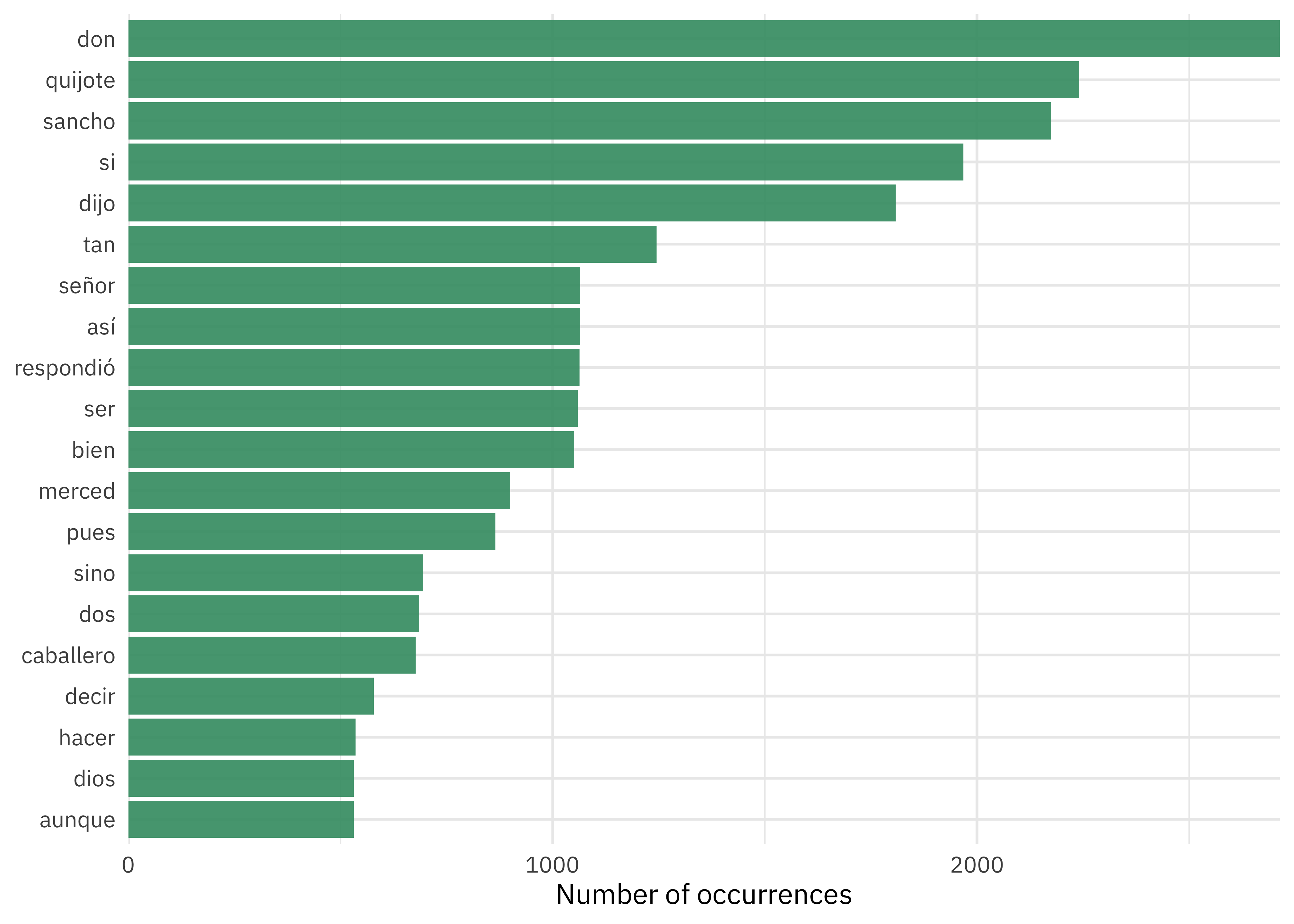
What are the most common words?
U N S C R A M B L E
anti_join(get_stopwords(language = "es")) |>
tidy_book |>
count(word, sort = TRUE) |>
geom_col()
slice_max(n, n = 20) |>
ggplot(aes(n, fct_reorder(word, n))) + What are the most common words?
WHAT IS A DOCUMENT ABOUT? 🤔
What is a document about?
- Term frequency
- Inverse document frequency
\[idf(\text{term}) = \ln{\left(\frac{n_{\text{documents}}}{n_{\text{documents containing term}}}\right)}\]
Tip
tf-idf is about comparing documents within a collection.
Understanding tf-idf
Make a collection (corpus) for yourself! 💅
Understanding tf-idf
Make a collection (corpus) for yourself! 💅
full_collection
#> # A tibble: 55,657 × 3
#> gutenberg_id text title
#> <int> <chr> <chr>
#> 1 2000 "El ingenioso hidalgo don Quijote de la Mancha" Don Quijote
#> 2 2000 "" Don Quijote
#> 3 2000 "" Don Quijote
#> 4 2000 "" Don Quijote
#> 5 2000 "por Miguel de Cervantes Saavedra" Don Quijote
#> 6 2000 "" Don Quijote
#> 7 2000 "" Don Quijote
#> 8 2000 "" Don Quijote
#> 9 2000 "" Don Quijote
#> 10 2000 "" Don Quijote
#> # ℹ 55,647 more rowsCounting word frequencies
book_words <- full_collection |>
unnest_tokens(word, text) |>
count(title, word, sort = TRUE)
book_words
#> # A tibble: 44,626 × 3
#> title word n
#> <chr> <chr> <int>
#> 1 Don Quijote que 20769
#> 2 Don Quijote de 18410
#> 3 Don Quijote y 18272
#> 4 Don Quijote la 10492
#> 5 Don Quijote a 9875
#> 6 Don Quijote en 8285
#> 7 Don Quijote el 8265
#> 8 Don Quijote no 6346
#> 9 Don Quijote los 4769
#> 10 Don Quijote se 4752
#> # ℹ 44,616 more rowsTip
What do the columns of book_words tell us?
Calculating tf-idf
Calculating tf-idf
book_tf_idf
#> # A tibble: 44,626 × 6
#> title word n tf idf tf_idf
#> <chr> <chr> <int> <dbl> <dbl> <dbl>
#> 1 Don Quijote que 20769 0.0541 0 0
#> 2 Don Quijote de 18410 0.0480 0 0
#> 3 Don Quijote y 18272 0.0476 0 0
#> 4 Don Quijote la 10492 0.0273 0 0
#> 5 Don Quijote a 9875 0.0257 0 0
#> 6 Don Quijote en 8285 0.0216 0 0
#> 7 Don Quijote el 8265 0.0215 0 0
#> 8 Don Quijote no 6346 0.0165 0 0
#> 9 Don Quijote los 4769 0.0124 0 0
#> 10 Don Quijote se 4752 0.0124 0 0
#> # ℹ 44,616 more rowsThat’s… super exciting??? 🥴
Calculating tf-idf
What do you predict will happen if we run the following code? 🤔
Calculating tf-idf
What do you predict will happen if we run the following code? 🤔
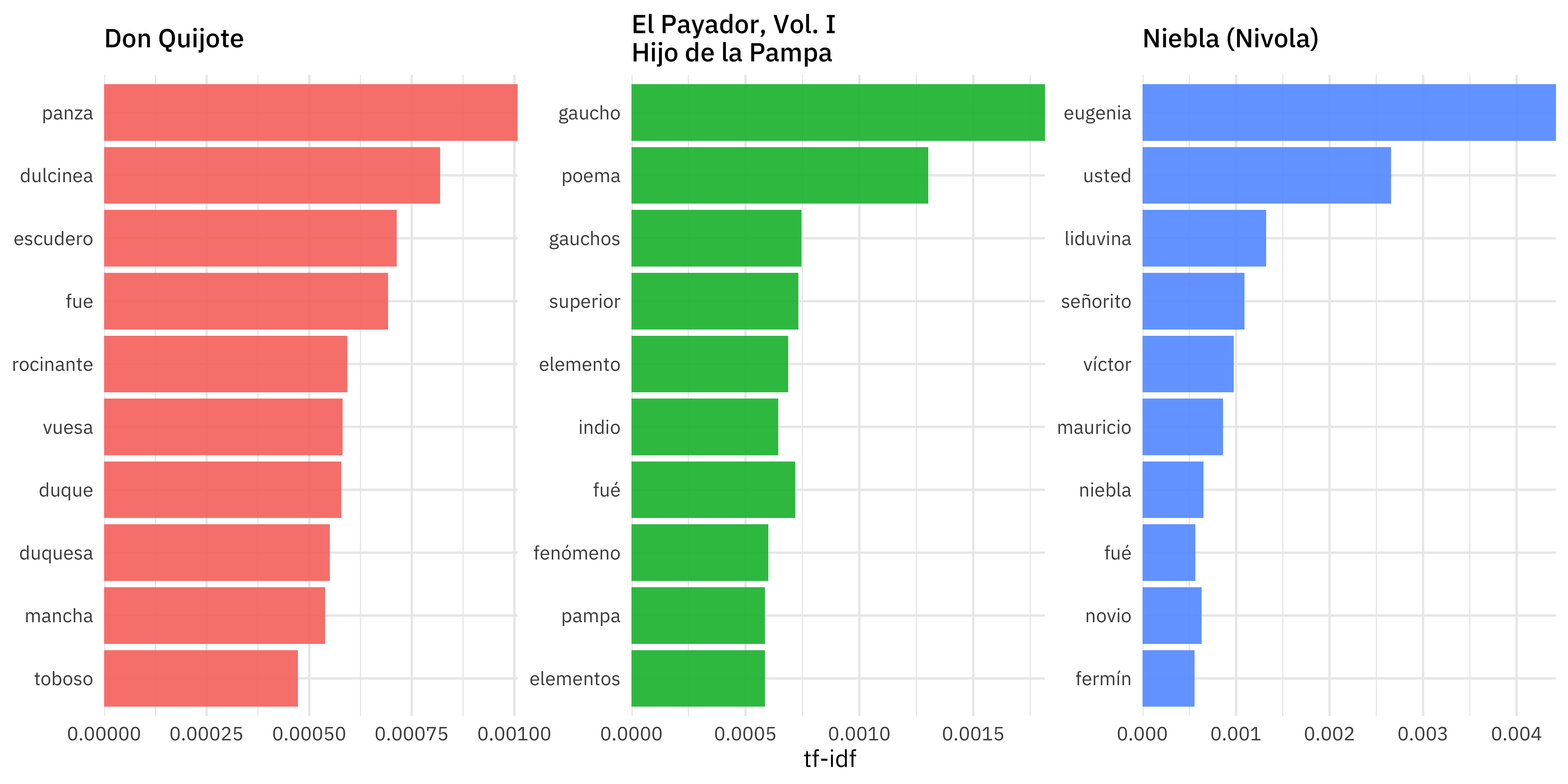
book_tf_idf |>
arrange(-tf_idf)
#> # A tibble: 44,626 × 6
#> title word n tf idf tf_idf
#> <chr> <chr> <int> <dbl> <dbl> <dbl>
#> 1 "Niebla (Nivola)" eugenia 231 0.00403 1.10 0.00442
#> 2 "Niebla (Nivola)" usted 376 0.00655 0.405 0.00266
#> 3 "El Payador, Vol. I\nHijo de la Pampa" gaucho 124 0.00165 1.10 0.00182
#> 4 "Niebla (Nivola)" liduvina 69 0.00120 1.10 0.00132
#> 5 "El Payador, Vol. I\nHijo de la Pampa" poema 89 0.00119 1.10 0.00130
#> 6 "Niebla (Nivola)" señorito 57 0.000993 1.10 0.00109
#> 7 "Don Quijote" panza 352 0.000918 1.10 0.00101
#> 8 "Niebla (Nivola)" víctor 51 0.000889 1.10 0.000976
#> 9 "Niebla (Nivola)" mauricio 45 0.000784 1.10 0.000861
#> 10 "Don Quijote" dulcinea 286 0.000745 1.10 0.000819
#> # ℹ 44,616 more rowsCalculating tf-idf
U N S C R A M B L E
group_by(title) |>
book_tf_idf |>
slice_max(tf_idf, n = 10) |>
ggplot(aes(tf_idf, fct_reorder(word, tf_idf), fill = title)) +
facet_wrap(vars(title), scales = "free")
geom_col(show.legend = FALSE) +Calculating tf-idf
WHAT IS A DOCUMENT ABOUT? 🤔
What is a document about?
- Term frequency
- Inverse document frequency
Weighted log odds ⚖️
- Log odds ratio expresses probabilities
- Weighting helps deal with power law distribution
Weighted log odds ⚖️
library(tidylo)
book_words |>
bind_log_odds(title, word, n) |>
arrange(-log_odds_weighted)
#> # A tibble: 44,626 × 4
#> title word n log_odds_weighted
#> <chr> <chr> <int> <dbl>
#> 1 "Niebla (Nivola)" eugenia 231 20.7
#> 2 "Niebla (Nivola)" usted 376 20.2
#> 3 "Niebla (Nivola)" augusto 372 14.8
#> 4 "El Payador, Vol. I\nHijo de la Pampa" la 3895 14.7
#> 5 "Don Quijote" panza 352 14.3
#> 6 "El Payador, Vol. I\nHijo de la Pampa" gaucho 124 14.3
#> 7 "Don Quijote" dulcinea 286 12.9
#> 8 "Niebla (Nivola)" no 1541 12.5
#> 9 "El Payador, Vol. I\nHijo de la Pampa" poema 89 12.1
#> 10 "Don Quijote" escudero 249 12.1
#> # ℹ 44,616 more rowsTip
Weighted log odds can distinguish between words that are used in all texts.
N-GRAMS… AND BEYOND! 🚀
N-grams… and beyond! 🚀
N-grams… and beyond! 🚀
tidy_ngram
#> # A tibble: 351,706 × 2
#> gutenberg_id bigram
#> <int> <chr>
#> 1 2000 el ingenioso
#> 2 2000 ingenioso hidalgo
#> 3 2000 hidalgo don
#> 4 2000 don quijote
#> 5 2000 quijote de
#> 6 2000 de la
#> 7 2000 la mancha
#> 8 2000 por miguel
#> 9 2000 miguel de
#> 10 2000 de cervantes
#> # ℹ 351,696 more rowsN-grams… and beyond! 🚀
Tip
Can we use an anti_join() now to remove the stop words?
N-grams… and beyond! 🚀
N-grams… and beyond! 🚀
bigram_counts
#> # A tibble: 41,129 × 3
#> word1 word2 n
#> <chr> <chr> <int>
#> 1 don quijote 2061
#> 2 respondió sancho 303
#> 3 dijo don 296
#> 4 sancho panza 281
#> 5 respondió don 265
#> 6 dijo sancho 236
#> 7 vuesa merced 180
#> 8 señor don 176
#> 9 don fernando 120
#> 10 caballero andante 104
#> # ℹ 41,119 more rowsWhat can you do with n-grams?
- tf-idf of n-grams
- weighted log odds of n-grams
- network analysis
- negation
Network analysis
Network analysis
bigram_graph
#> # A tbl_graph: 86 nodes and 73 edges
#> #
#> # A directed simple graph with 21 components
#> #
#> # Node Data: 86 × 1 (active)
#> name
#> <chr>
#> 1 don
#> 2 respondió
#> 3 dijo
#> 4 sancho
#> 5 vuesa
#> 6 señor
#> 7 caballero
#> 8 caballeros
#> 9 merced
#> 10 señora
#> # ℹ 76 more rows
#> #
#> # Edge Data: 73 × 3
#> from to n
#> <int> <int> <int>
#> 1 1 29 2061
#> 2 2 4 303
#> 3 3 1 296
#> # ℹ 70 more rowsNetwork analysis
Network analysis

Thanks!
Slides created with Quarto