Tidy Topic Modeling
Julia Silge and David Robinson
2026-06-27
Source:vignettes/articles/topic_modeling.Rmd
topic_modeling.RmdTopic modeling is a method for unsupervised classification of documents, by modeling each document as a mixture of topics and each topic as a mixture of words. Latent Dirichlet allocation is a particularly popular method for fitting a topic model.
We can use tidy text principles, as described in the main vignette, to approach topic modeling using consistent and effective tools. In particular, we’ll be using tidying functions for LDA objects from the topicmodels package.
Can we tell the difference between Dickens, Wells, Verne, and Austen?
Suppose a vandal has broken into your study and torn apart four of your books:
- Great Expectations by Charles Dickens
- The War of the Worlds by H.G. Wells
- Twenty Thousand Leagues Under the Sea by Jules Verne
- Pride and Prejudice by Jane Austen
This vandal has torn the books into individual chapters, and left them in one large pile. How can we restore these disorganized chapters to their original books?
Setup
titles <- c(
"Twenty Thousand Leagues under the Sea",
"The War of the Worlds",
"Pride and Prejudice",
"Great Expectations"
)
books <- gutenberg_works(title %in% titles) |>
gutenberg_download(meta_fields = "title")
books## # A tibble: 51,663 × 3
## gutenberg_id text title
## <int> <chr> <chr>
## 1 36 "The War of the Worlds" The …
## 2 36 "" The …
## 3 36 "by H. G. Wells [1898]" The …
## 4 36 "" The …
## 5 36 "" The …
## 6 36 " But who shall dwell in these worlds if they be" The …
## 7 36 " inhabited? . . . Are we or they Lords of the" The …
## 8 36 " World? . . . And how are all things made for man… The …
## 9 36 " KEPLER (quoted in The Anatomy of Melancholy)" The …
## 10 36 "" The …
## # ℹ 51,653 more rowsAs pre-processing, we divide these into chapters, use tidytext’s
unnest_tokens to separate them into words, then remove
stop_words.1 We’re treating every chapter as a separate
“document”, each with a name like Great Expectations_1 or
Pride and Prejudice_11.
library(tidytext)
library(stringr)
library(tidyr)
by_chapter <- books |>
group_by(title) |>
mutate(
chapter = cumsum(str_detect(text, regex("^chapter ", ignore_case = TRUE)))
) |>
ungroup() |>
filter(chapter > 0)
by_chapter_word <- by_chapter |>
unite(title_chapter, title, chapter) |>
unnest_tokens(word, text)
word_counts <- by_chapter_word |>
anti_join(stop_words) |>
count(title_chapter, word, sort = TRUE)
word_counts## # A tibble: 104,704 × 3
## title_chapter word n
## <chr> <chr> <int>
## 1 Great Expectations_57 joe 88
## 2 Great Expectations_7 joe 70
## 3 Great Expectations_17 biddy 63
## 4 Great Expectations_27 joe 58
## 5 Great Expectations_38 estella 58
## 6 Great Expectations_2 joe 56
## 7 Great Expectations_23 pocket 53
## 8 Great Expectations_15 joe 50
## 9 Great Expectations_18 joe 50
## 10 The War of the Worlds_16 brother 50
## # ℹ 104,694 more rowsLatent Dirichlet Allocation with the topicmodels package
Right now this data frame is in a tidy form, with
one-term-per-document-per-row. However, the topicmodels package requires
a DocumentTermMatrix (from the tm package). As described in
this vignette, we can cast a
one-token-per-row table into a DocumentTermMatrix with
tidytext’s cast_dtm:
chapters_dtm <- word_counts |>
cast_dtm(title_chapter, word, n)
chapters_dtm## <<DocumentTermMatrix (documents: 193, terms: 18202)>>
## Non-/sparse entries: 104704/3408282
## Sparsity : 97%
## Maximal term length: 19
## Weighting : term frequency (tf)Now we are ready to use the topicmodels package to create a four topic LDA model.
library(topicmodels)
chapters_lda <- LDA(chapters_dtm, k = 4, control = list(seed = 1234))
chapters_lda## A LDA_VEM topic model with 4 topics.(In this case we know there are four topics because there are four
books; in practice we may need to try a few different values of
k).
Now tidytext gives us the option of returning to a tidy
analysis, using the tidy and augment verbs
borrowed from the broom
package. In particular, we start with the tidy
verb.
chapters_lda_td <- tidy(chapters_lda)
chapters_lda_td## # A tibble: 72,808 × 3
## topic term beta
## <int> <chr> <dbl>
## 1 1 joe 1.41e- 16
## 2 2 joe 5.13e- 54
## 3 3 joe 1.40e- 2
## 4 4 joe 2.75e- 39
## 5 1 biddy 3.96e- 22
## 6 2 biddy 5.72e- 62
## 7 3 biddy 4.63e- 3
## 8 4 biddy 3.24e- 47
## 9 1 estella 4.19e- 18
## 10 2 estella 2.09e-136
## # ℹ 72,798 more rowsNotice that this has turned the model into a one-topic-per-term-per-row format. For each combination the model has , the probability of that term being generated from that topic.
We could use dplyr’s slice_max() to find the top 5 terms
within each topic:
top_terms <- chapters_lda_td |>
group_by(topic) |>
slice_max(beta, n = 5) |>
ungroup() |>
arrange(topic, -beta)
top_terms## # A tibble: 20 × 3
## topic term beta
## <int> <chr> <dbl>
## 1 1 people 0.00629
## 2 1 martians 0.00590
## 3 1 time 0.00550
## 4 1 black 0.00501
## 5 1 night 0.00464
## 6 2 captain 0.0154
## 7 2 nautilus 0.0131
## 8 2 sea 0.00883
## 9 2 nemo 0.00876
## 10 2 ned 0.00808
## 11 3 joe 0.0140
## 12 3 miss 0.00757
## 13 3 time 0.00675
## 14 3 pip 0.00661
## 15 3 looked 0.00618
## 16 4 elizabeth 0.0155
## 17 4 darcy 0.00971
## 18 4 bennet 0.00765
## 19 4 miss 0.00764
## 20 4 jane 0.00714This model lends itself to a visualization:
library(ggplot2)
theme_set(theme_bw())
top_terms |>
mutate(term = reorder_within(term, beta, topic)) |>
ggplot(aes(term, beta)) +
geom_col() +
scale_x_reordered() +
facet_wrap(vars(topic), scales = "free_x")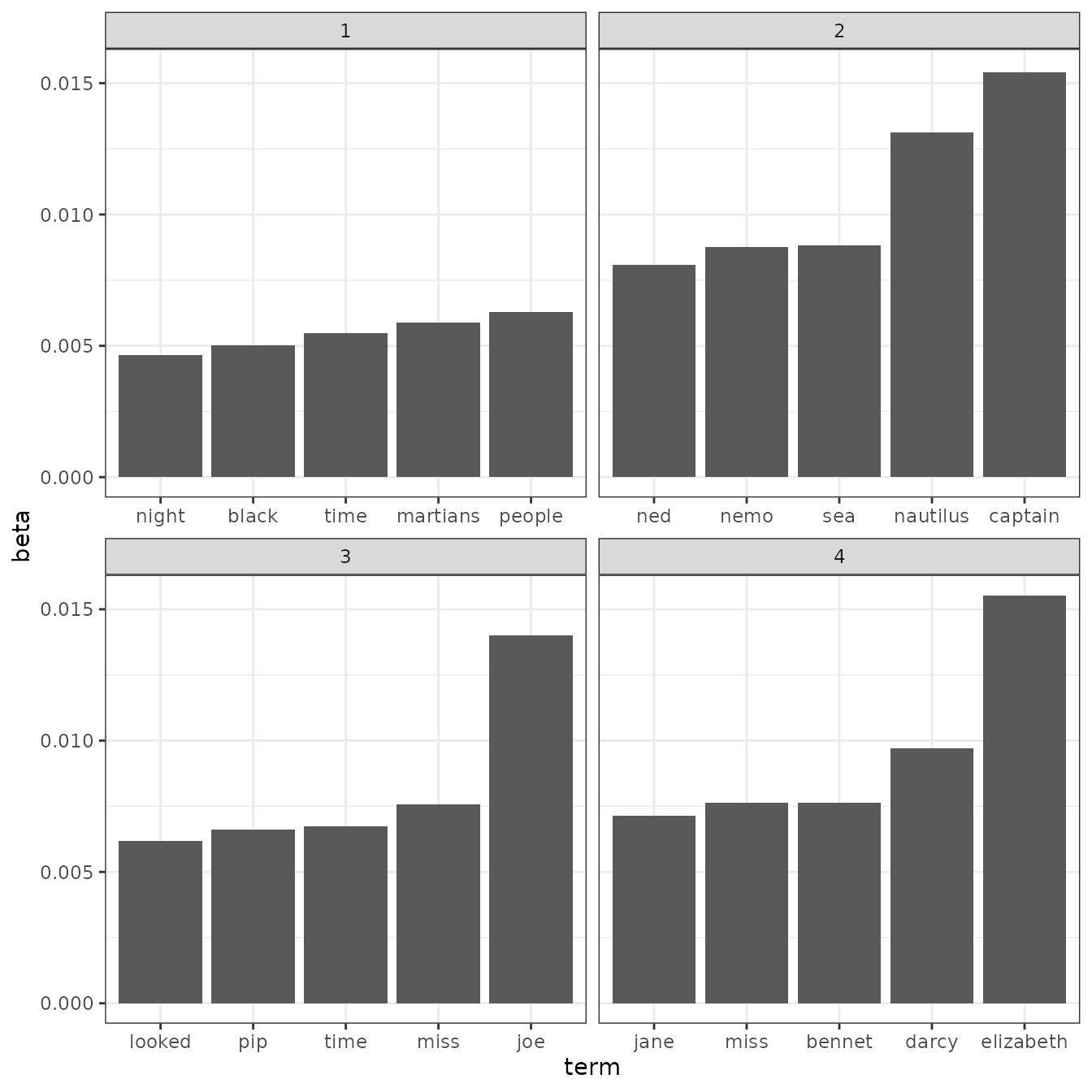
These topics are pretty clearly associated with the four books! There’s no question that the topic of “nemo”, “sea”, and “nautilus” belongs to Twenty Thousand Leagues Under the Sea, and that “jane”, “darcy”, and “elizabeth” belongs to Pride and Prejudice. We see “pip” and “joe” from Great Expectations and “martians”, “black”, and “night” from The War of the Worlds.
Per-document classification
Each chapter was a “document” in this analysis. Thus, we may want to know which topics are associated with each document. Can we put the chapters back together in the correct books?
chapters_lda_gamma <- tidy(chapters_lda, matrix = "gamma")
chapters_lda_gamma## # A tibble: 772 × 3
## document topic gamma
## <chr> <int> <dbl>
## 1 Great Expectations_57 1 0.0000134
## 2 Great Expectations_7 1 0.0000146
## 3 Great Expectations_17 1 0.0000210
## 4 Great Expectations_27 1 0.0000190
## 5 Great Expectations_38 1 0.0000127
## 6 Great Expectations_2 1 0.0000171
## 7 Great Expectations_23 1 0.290
## 8 Great Expectations_15 1 0.0000143
## 9 Great Expectations_18 1 0.0000126
## 10 The War of the Worlds_16 1 1.000
## # ℹ 762 more rowsSetting matrix = "gamma" returns a tidied version with
one-document-per-topic-per-row. Now that we have these document
classifications, we can see how well our unsupervised learning did at
distinguishing the four books. First we re-separate the document name
into title and chapter:
chapters_lda_gamma <- chapters_lda_gamma |>
separate(document, c("title", "chapter"), sep = "_", convert = TRUE)
chapters_lda_gamma## # A tibble: 772 × 4
## title chapter topic gamma
## <chr> <int> <int> <dbl>
## 1 Great Expectations 57 1 0.0000134
## 2 Great Expectations 7 1 0.0000146
## 3 Great Expectations 17 1 0.0000210
## 4 Great Expectations 27 1 0.0000190
## 5 Great Expectations 38 1 0.0000127
## 6 Great Expectations 2 1 0.0000171
## 7 Great Expectations 23 1 0.290
## 8 Great Expectations 15 1 0.0000143
## 9 Great Expectations 18 1 0.0000126
## 10 The War of the Worlds 16 1 1.000
## # ℹ 762 more rowsThen we examine what fraction of chapters we got right for each:
ggplot(chapters_lda_gamma, aes(gamma, fill = factor(topic))) +
geom_histogram() +
facet_wrap(vars(title), nrow = 2)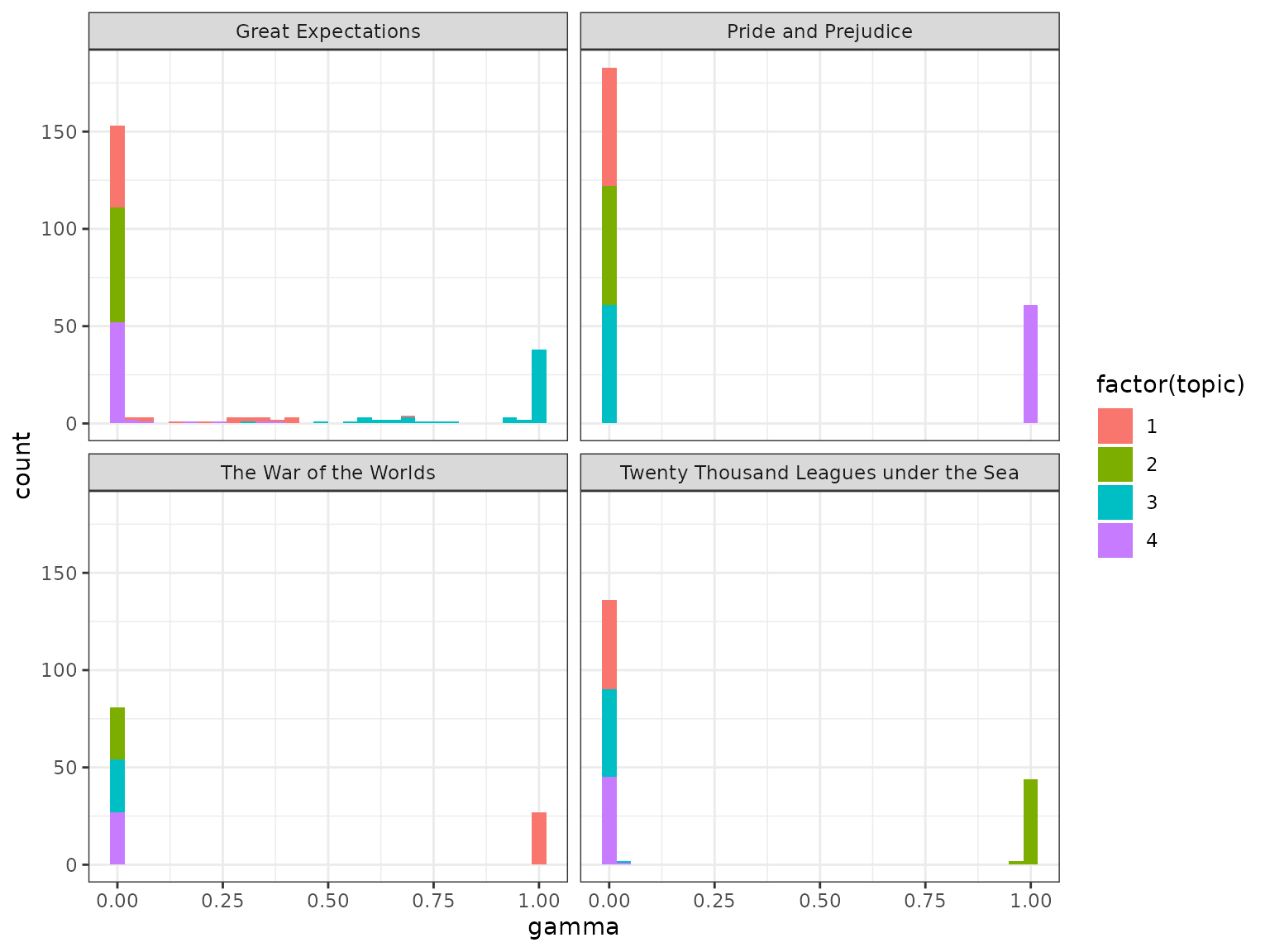
We notice that almost all of the chapters from Pride and Prejudice, War of the Worlds, and Twenty Thousand Leagues Under the Sea were uniquely identified as a single topic each.
chapter_classifications <- chapters_lda_gamma |>
group_by(title, chapter) |>
slice_max(gamma, n = 1) |>
ungroup() |>
arrange(gamma)
chapter_classifications## # A tibble: 193 × 4
## title chapter topic gamma
## <chr> <int> <int> <dbl>
## 1 Great Expectations 56 3 0.499
## 2 Great Expectations 23 3 0.553
## 3 Great Expectations 3 3 0.579
## 4 Great Expectations 21 3 0.588
## 5 Great Expectations 1 3 0.597
## 6 Great Expectations 46 3 0.606
## 7 Great Expectations 55 3 0.618
## 8 Great Expectations 5 3 0.647
## 9 Great Expectations 20 3 0.647
## 10 Great Expectations 32 3 0.686
## # ℹ 183 more rowsWe can determine this by finding the consensus book for each, which we note is correct based on our earlier visualization:
book_topics <- chapter_classifications |>
count(title, topic) |>
group_by(topic) |>
slice_max(n, n = 1) |>
ungroup() |>
transmute(consensus = title, topic)
book_topics## # A tibble: 4 × 2
## consensus topic
## <chr> <int>
## 1 The War of the Worlds 1
## 2 Twenty Thousand Leagues under the Sea 2
## 3 Great Expectations 3
## 4 Pride and Prejudice 4Then we see which chapters were misidentified:
chapter_classifications |>
inner_join(book_topics, by = "topic") |>
count(title, consensus)## # A tibble: 5 × 3
## title consensus n
## <chr> <chr> <int>
## 1 Great Expectations Great Expectations 58
## 2 Great Expectations The War of the Worlds 1
## 3 Pride and Prejudice Pride and Prejudice 61
## 4 The War of the Worlds The War of the Worlds 27
## 5 Twenty Thousand Leagues under the Sea Twenty Thousand Leagues under the… 46We see that only a few chapters from Great Expectations were misclassified. Not bad for unsupervised clustering!
By word assignments: augment
One important step in the topic modeling expectation-maximization
algorithm is assigning each word in each document to a topic. The more
words in a document are assigned to that topic, generally, the more
weight (gamma) will go on that document-topic
classification.
We may want to take the original document-word pairs and find which
words in each document were assigned to which topic. This is the job of
the augment verb.
assignments <- augment(chapters_lda, data = chapters_dtm)We can combine this with the consensus book titles to find which words were incorrectly classified.
assignments <- assignments |>
separate(document, c("title", "chapter"), sep = "_", convert = TRUE) |>
inner_join(book_topics, join_by(.topic == topic))
assignments## # A tibble: 104,704 × 6
## title chapter term count .topic consensus
## <chr> <int> <chr> <dbl> <dbl> <chr>
## 1 Great Expectations 57 joe 88 3 Great Expectations
## 2 Great Expectations 7 joe 70 3 Great Expectations
## 3 Great Expectations 17 joe 5 3 Great Expectations
## 4 Great Expectations 27 joe 58 3 Great Expectations
## 5 Great Expectations 2 joe 56 3 Great Expectations
## 6 Great Expectations 23 joe 1 3 Great Expectations
## 7 Great Expectations 15 joe 50 3 Great Expectations
## 8 Great Expectations 18 joe 50 3 Great Expectations
## 9 Great Expectations 9 joe 44 3 Great Expectations
## 10 Great Expectations 13 joe 40 3 Great Expectations
## # ℹ 104,694 more rowsWe can, for example, create a “confusion matrix” using dplyr’s
count() and tidyr’s pivot_wider():
assignments |>
count(title, consensus, wt = count) |>
pivot_wider(names_from = consensus, values_from = n, values_fill = 0)## # A tibble: 4 × 5
## title `Great Expectations` `Pride and Prejudice` The War of the World…¹
## <chr> <dbl> <dbl> <dbl>
## 1 Great Expec… 50635 733 4193
## 2 Pride and P… 0 37242 0
## 3 The War of … 0 0 22559
## 4 Twenty Thou… 3 1 0
## # ℹ abbreviated name: ¹`The War of the Worlds`
## # ℹ 1 more variable: `Twenty Thousand Leagues under the Sea` <dbl>We notice that almost all the words for Pride and Prejudice, Twenty Thousand Leagues Under the Sea, and War of the Worlds were correctly assigned, while Great Expectations had a fair amount of misassignment.
What were the most commonly mistaken words?
wrong_words <- assignments |>
filter(title != consensus)
wrong_words## # A tibble: 3,641 × 6
## title chapter term count .topic consensus
## <chr> <int> <chr> <dbl> <dbl> <chr>
## 1 Great Expectations 20 brother 1 1 The War …
## 2 Great Expectations 37 brother 2 4 Pride an…
## 3 Great Expectations 22 brother 4 4 Pride an…
## 4 Twenty Thousand Leagues under the Sea 8 miss 1 3 Great Ex…
## 5 Great Expectations 5 sergeant 37 1 The War …
## 6 Great Expectations 46 captain 1 1 The War …
## 7 Great Expectations 32 captain 1 1 The War …
## 8 The War of the Worlds 17 captain 5 2 Twenty T…
## 9 Great Expectations 54 sea 2 1 The War …
## 10 Great Expectations 1 sea 2 1 The War …
## # ℹ 3,631 more rows## # A tibble: 2,820 × 4
## title consensus term n
## <chr> <chr> <chr> <dbl>
## 1 Great Expectations The War of the Worlds boat 39
## 2 Great Expectations The War of the Worlds sergeant 37
## 3 Great Expectations The War of the Worlds river 34
## 4 Great Expectations The War of the Worlds jack 28
## 5 Great Expectations The War of the Worlds tide 28
## 6 Great Expectations The War of the Worlds water 25
## 7 Great Expectations The War of the Worlds black 19
## 8 Great Expectations The War of the Worlds soldiers 19
## 9 Great Expectations The War of the Worlds london 18
## 10 Great Expectations The War of the Worlds people 18
## # ℹ 2,810 more rowsIt seems like it is especially difficult to distinguish Great Expectations from The War of the Worlds.